Compare commits
20 Commits
reformat
...
concatenat
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
25652f0994 | ||
|
|
0b458bf82d | ||
|
|
ffd102e5c0 | ||
|
|
5543a5089d | ||
|
|
1dc464dcb0 | ||
|
|
962e33dc10 | ||
|
|
42ea6a3fc0 | ||
|
|
e563b015d8 | ||
|
|
1c413ed593 | ||
|
|
3f922d4bfb | ||
|
|
744bf7cbf2 | ||
|
|
768354239b | ||
|
|
6762e62a40 | ||
|
|
a453d4e9c4 | ||
|
|
ec979cd9c4 | ||
|
|
2c0018d946 | ||
|
|
8fa182cfa7 | ||
|
|
862aad637b | ||
|
|
46c4654226 | ||
|
|
ea6e77df72 |
@@ -1,7 +1,6 @@
|
|||||||
.env
|
.env
|
||||||
Dockerfile
|
Dockerfile
|
||||||
/characters
|
/characters
|
||||||
/extensions
|
|
||||||
/loras
|
/loras
|
||||||
/models
|
/models
|
||||||
/presets
|
/presets
|
||||||
|
|||||||
19
Dockerfile
19
Dockerfile
@@ -30,8 +30,7 @@ RUN apt-get update && \
|
|||||||
rm -rf /var/lib/apt/lists/*
|
rm -rf /var/lib/apt/lists/*
|
||||||
|
|
||||||
RUN --mount=type=cache,target=/root/.cache/pip pip3 install virtualenv
|
RUN --mount=type=cache,target=/root/.cache/pip pip3 install virtualenv
|
||||||
|
RUN mkdir /app
|
||||||
COPY . /app/
|
|
||||||
|
|
||||||
WORKDIR /app
|
WORKDIR /app
|
||||||
|
|
||||||
@@ -41,21 +40,29 @@ RUN test -n "${WEBUI_VERSION}" && git reset --hard ${WEBUI_VERSION} || echo "Usi
|
|||||||
RUN virtualenv /app/venv
|
RUN virtualenv /app/venv
|
||||||
RUN . /app/venv/bin/activate && \
|
RUN . /app/venv/bin/activate && \
|
||||||
pip3 install --upgrade pip setuptools && \
|
pip3 install --upgrade pip setuptools && \
|
||||||
pip3 install torch torchvision torchaudio && \
|
pip3 install torch torchvision torchaudio
|
||||||
pip3 install -r requirements.txt
|
|
||||||
|
|
||||||
COPY --from=builder /build /app/repositories/GPTQ-for-LLaMa
|
COPY --from=builder /build /app/repositories/GPTQ-for-LLaMa
|
||||||
RUN . /app/venv/bin/activate && \
|
RUN . /app/venv/bin/activate && \
|
||||||
pip3 install /app/repositories/GPTQ-for-LLaMa/*.whl
|
pip3 install /app/repositories/GPTQ-for-LLaMa/*.whl
|
||||||
|
|
||||||
ENV CLI_ARGS=""
|
COPY extensions/api/requirements.txt /app/extensions/api/requirements.txt
|
||||||
|
COPY extensions/elevenlabs_tts/requirements.txt /app/extensions/elevenlabs_tts/requirements.txt
|
||||||
|
COPY extensions/google_translate/requirements.txt /app/extensions/google_translate/requirements.txt
|
||||||
|
COPY extensions/silero_tts/requirements.txt /app/extensions/silero_tts/requirements.txt
|
||||||
|
COPY extensions/whisper_stt/requirements.txt /app/extensions/whisper_stt/requirements.txt
|
||||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/api && pip3 install -r requirements.txt
|
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/api && pip3 install -r requirements.txt
|
||||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/elevenlabs_tts && pip3 install -r requirements.txt
|
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/elevenlabs_tts && pip3 install -r requirements.txt
|
||||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/google_translate && pip3 install -r requirements.txt
|
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/google_translate && pip3 install -r requirements.txt
|
||||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/silero_tts && pip3 install -r requirements.txt
|
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/silero_tts && pip3 install -r requirements.txt
|
||||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/whisper_stt && pip3 install -r requirements.txt
|
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/whisper_stt && pip3 install -r requirements.txt
|
||||||
|
|
||||||
|
COPY requirements.txt /app/requirements.txt
|
||||||
|
RUN . /app/venv/bin/activate && \
|
||||||
|
pip3 install -r requirements.txt
|
||||||
|
|
||||||
RUN cp /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so
|
RUN cp /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so
|
||||||
|
|
||||||
|
COPY . /app/
|
||||||
|
ENV CLI_ARGS=""
|
||||||
CMD . /app/venv/bin/activate && python3 server.py ${CLI_ARGS}
|
CMD . /app/venv/bin/activate && python3 server.py ${CLI_ARGS}
|
||||||
|
|||||||
22
README.md
22
README.md
@@ -119,7 +119,7 @@ As an alternative to the recommended WSL method, you can install the web UI nati
|
|||||||
|
|
||||||
```
|
```
|
||||||
cp .env.example .env
|
cp .env.example .env
|
||||||
docker-compose up --build
|
docker compose up --build
|
||||||
```
|
```
|
||||||
|
|
||||||
Make sure to edit `.env.example` and set the appropriate CUDA version for your GPU.
|
Make sure to edit `.env.example` and set the appropriate CUDA version for your GPU.
|
||||||
@@ -192,14 +192,14 @@ Optionally, you can use the following command-line flags:
|
|||||||
#### Basic settings
|
#### Basic settings
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|--------------------------------------------|-------------|
|
||||||
| `-h`, `--help` | show this help message and exit |
|
| `-h`, `--help` | Show this help message and exit. |
|
||||||
| `--notebook` | Launch the web UI in notebook mode, where the output is written to the same text box as the input. |
|
| `--notebook` | Launch the web UI in notebook mode, where the output is written to the same text box as the input. |
|
||||||
| `--chat` | Launch the web UI in chat mode. |
|
| `--chat` | Launch the web UI in chat mode. |
|
||||||
| `--model MODEL` | Name of the model to load by default. |
|
| `--model MODEL` | Name of the model to load by default. |
|
||||||
| `--lora LORA` | Name of the LoRA to apply to the model by default. |
|
| `--lora LORA` | Name of the LoRA to apply to the model by default. |
|
||||||
| `--model-dir MODEL_DIR` | Path to directory with all the models |
|
| `--model-dir MODEL_DIR` | Path to directory with all the models. |
|
||||||
| `--lora-dir LORA_DIR` | Path to directory with all the loras |
|
| `--lora-dir LORA_DIR` | Path to directory with all the loras. |
|
||||||
| `--no-stream` | Don't stream the text output in real time. |
|
| `--no-stream` | Don't stream the text output in real time. |
|
||||||
| `--settings SETTINGS_FILE` | Load the default interface settings from this json file. See `settings-template.json` for an example. If you create a file called `settings.json`, this file will be loaded by default without the need to use the `--settings` flag. |
|
| `--settings SETTINGS_FILE` | Load the default interface settings from this json file. See `settings-template.json` for an example. If you create a file called `settings.json`, this file will be loaded by default without the need to use the `--settings` flag. |
|
||||||
| `--extensions EXTENSIONS [EXTENSIONS ...]` | The list of extensions to load. If you want to load more than one extension, write the names separated by spaces. |
|
| `--extensions EXTENSIONS [EXTENSIONS ...]` | The list of extensions to load. If you want to load more than one extension, write the names separated by spaces. |
|
||||||
@@ -208,7 +208,7 @@ Optionally, you can use the following command-line flags:
|
|||||||
#### Accelerate/transformers
|
#### Accelerate/transformers
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|---------------------------------------------|-------------|
|
||||||
| `--cpu` | Use the CPU to generate text. |
|
| `--cpu` | Use the CPU to generate text. |
|
||||||
| `--auto-devices` | Automatically split the model across the available GPU(s) and CPU. |
|
| `--auto-devices` | Automatically split the model across the available GPU(s) and CPU. |
|
||||||
| `--gpu-memory GPU_MEMORY [GPU_MEMORY ...]` | Maxmimum GPU memory in GiB to be allocated per GPU. Example: `--gpu-memory 10` for a single GPU, `--gpu-memory 10 5` for two GPUs. You can also set values in MiB like `--gpu-memory 3500MiB`. |
|
| `--gpu-memory GPU_MEMORY [GPU_MEMORY ...]` | Maxmimum GPU memory in GiB to be allocated per GPU. Example: `--gpu-memory 10` for a single GPU, `--gpu-memory 10 5` for two GPUs. You can also set values in MiB like `--gpu-memory 3500MiB`. |
|
||||||
@@ -222,13 +222,13 @@ Optionally, you can use the following command-line flags:
|
|||||||
#### llama.cpp
|
#### llama.cpp
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|-------------|-------------|
|
||||||
| `--threads` | Number of threads to use in llama.cpp. |
|
| `--threads` | Number of threads to use in llama.cpp. |
|
||||||
|
|
||||||
#### GPTQ
|
#### GPTQ
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|---------------------------|-------------|
|
||||||
| `--wbits WBITS` | GPTQ: Load a pre-quantized model with specified precision in bits. 2, 3, 4 and 8 are supported. |
|
| `--wbits WBITS` | GPTQ: Load a pre-quantized model with specified precision in bits. 2, 3, 4 and 8 are supported. |
|
||||||
| `--model_type MODEL_TYPE` | GPTQ: Model type of pre-quantized model. Currently LLaMA, OPT, and GPT-J are supported. |
|
| `--model_type MODEL_TYPE` | GPTQ: Model type of pre-quantized model. Currently LLaMA, OPT, and GPT-J are supported. |
|
||||||
| `--groupsize GROUPSIZE` | GPTQ: Group size. |
|
| `--groupsize GROUPSIZE` | GPTQ: Group size. |
|
||||||
@@ -246,7 +246,7 @@ Optionally, you can use the following command-line flags:
|
|||||||
#### DeepSpeed
|
#### DeepSpeed
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|---------------------------------------|-------------|
|
||||||
| `--deepspeed` | Enable the use of DeepSpeed ZeRO-3 for inference via the Transformers integration. |
|
| `--deepspeed` | Enable the use of DeepSpeed ZeRO-3 for inference via the Transformers integration. |
|
||||||
| `--nvme-offload-dir NVME_OFFLOAD_DIR` | DeepSpeed: Directory to use for ZeRO-3 NVME offloading. |
|
| `--nvme-offload-dir NVME_OFFLOAD_DIR` | DeepSpeed: Directory to use for ZeRO-3 NVME offloading. |
|
||||||
| `--local_rank LOCAL_RANK` | DeepSpeed: Optional argument for distributed setups. |
|
| `--local_rank LOCAL_RANK` | DeepSpeed: Optional argument for distributed setups. |
|
||||||
@@ -254,14 +254,14 @@ Optionally, you can use the following command-line flags:
|
|||||||
#### RWKV
|
#### RWKV
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|---------------------------------|-------------|
|
||||||
| `--rwkv-strategy RWKV_STRATEGY` | RWKV: The strategy to use while loading the model. Examples: "cpu fp32", "cuda fp16", "cuda fp16i8". |
|
| `--rwkv-strategy RWKV_STRATEGY` | RWKV: The strategy to use while loading the model. Examples: "cpu fp32", "cuda fp16", "cuda fp16i8". |
|
||||||
| `--rwkv-cuda-on` | RWKV: Compile the CUDA kernel for better performance. |
|
| `--rwkv-cuda-on` | RWKV: Compile the CUDA kernel for better performance. |
|
||||||
|
|
||||||
#### Gradio
|
#### Gradio
|
||||||
|
|
||||||
| Flag | Description |
|
| Flag | Description |
|
||||||
|------------------|-------------|
|
|---------------------------------------|-------------|
|
||||||
| `--listen` | Make the web UI reachable from your local network. |
|
| `--listen` | Make the web UI reachable from your local network. |
|
||||||
| `--listen-port LISTEN_PORT` | The listening port that the server will use. |
|
| `--listen-port LISTEN_PORT` | The listening port that the server will use. |
|
||||||
| `--share` | Create a public URL. This is useful for running the web UI on Google Colab or similar. |
|
| `--share` | Create a public URL. This is useful for running the web UI on Google Colab or similar. |
|
||||||
|
|||||||
@@ -36,3 +36,8 @@ div.svelte-362y77>*, div.svelte-362y77>.form>* {
|
|||||||
.wrap.svelte-6roggh.svelte-6roggh {
|
.wrap.svelte-6roggh.svelte-6roggh {
|
||||||
max-height: 92.5%;
|
max-height: 92.5%;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
/* This is for the microphone button in the whisper extension */
|
||||||
|
.sm.svelte-1ipelgc {
|
||||||
|
width: 100%;
|
||||||
|
}
|
||||||
|
|||||||
@@ -2,10 +2,11 @@ import re
|
|||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
|
|
||||||
import gradio as gr
|
import gradio as gr
|
||||||
import modules.shared as shared
|
|
||||||
from elevenlabslib import ElevenLabsUser
|
from elevenlabslib import ElevenLabsUser
|
||||||
from elevenlabslib.helpers import save_bytes_to_path
|
from elevenlabslib.helpers import save_bytes_to_path
|
||||||
|
|
||||||
|
import modules.shared as shared
|
||||||
|
|
||||||
params = {
|
params = {
|
||||||
'activate': True,
|
'activate': True,
|
||||||
'api_key': '12345',
|
'api_key': '12345',
|
||||||
|
|||||||
@@ -1,7 +1,8 @@
|
|||||||
import gradio as gr
|
import gradio as gr
|
||||||
import modules.shared as shared
|
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
|
|
||||||
|
import modules.shared as shared
|
||||||
|
|
||||||
df = pd.read_csv("https://raw.githubusercontent.com/devbrones/llama-prompts/main/prompts/prompts.csv")
|
df = pd.read_csv("https://raw.githubusercontent.com/devbrones/llama-prompts/main/prompts/prompts.csv")
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
78
extensions/sd_api_pictures/README.MD
Normal file
78
extensions/sd_api_pictures/README.MD
Normal file
@@ -0,0 +1,78 @@
|
|||||||
|
## Description:
|
||||||
|
TL;DR: Lets the bot answer you with a picture!
|
||||||
|
|
||||||
|
Stable Diffusion API pictures for TextGen, v.1.1.0
|
||||||
|
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Interface overview</summary>
|
||||||
|
|
||||||
|
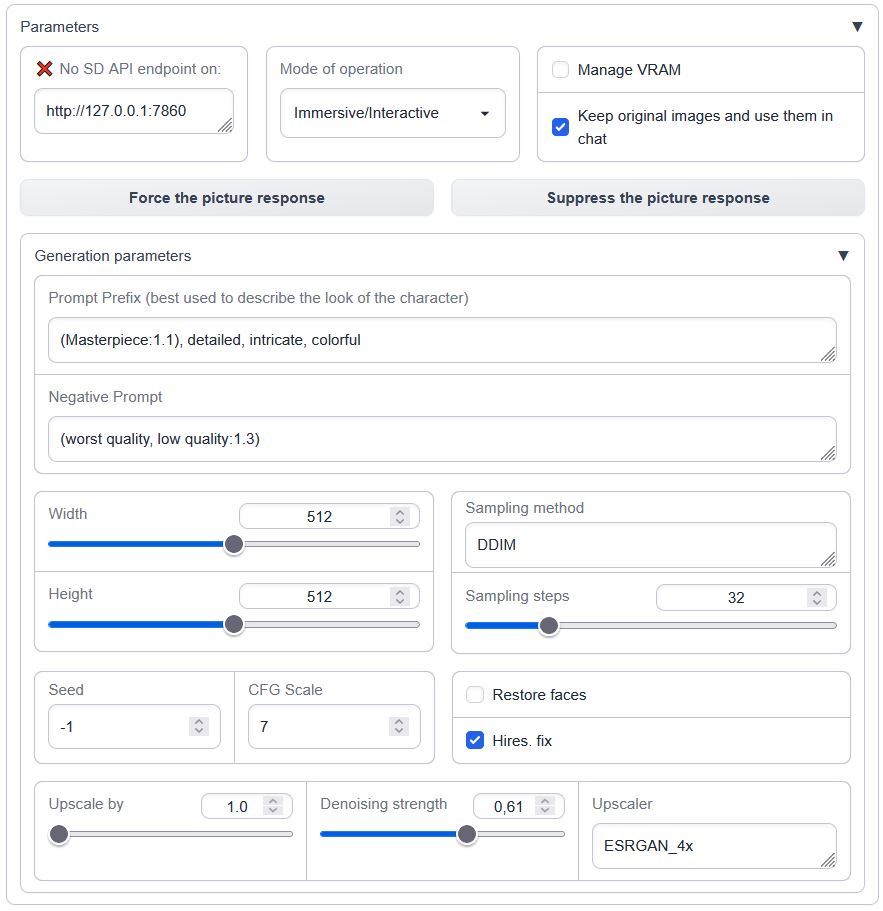
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures` (it's not really required, but completes the picture, *pun intended*).
|
||||||
|
|
||||||
|
The image generation is triggered either:
|
||||||
|
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
||||||
|
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
||||||
|
- always on in Picturebook/Adventure mode (if not currently suppressed by 'Suppress the picture response')
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
||||||
|
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
||||||
|
|
||||||
|
## Features:
|
||||||
|
- API detection (press enter in the API box)
|
||||||
|
- VRAM management (model shuffling)
|
||||||
|
- Three different operation modes (manual, interactive, always-on)
|
||||||
|
- persistent settings via settings.json
|
||||||
|
|
||||||
|
The model input is modified only in the interactive mode; other two are unaffected. The output pic description is presented differently for Picture-book / Adventure mode.
|
||||||
|
|
||||||
|
Connection check (insert the Auto1111's address and press Enter):
|
||||||
|
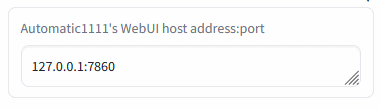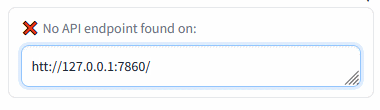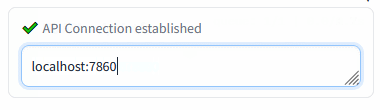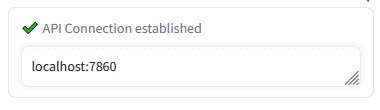
|
||||||
|
|
||||||
|
### Persistents settings
|
||||||
|
|
||||||
|
Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
|
||||||
|
present in script.py, ex:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"sd_api_pictures-manage_VRAM": 1,
|
||||||
|
"sd_api_pictures-save_img": 1,
|
||||||
|
"sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
|
||||||
|
"sd_api_pictures-sampler_name": "DPM++ 2M Karras"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Demonstrations:
|
||||||
|
|
||||||
|
Those are examples of the version 1.0.0, but the core functionality is still the same
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Conversation 1</summary>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
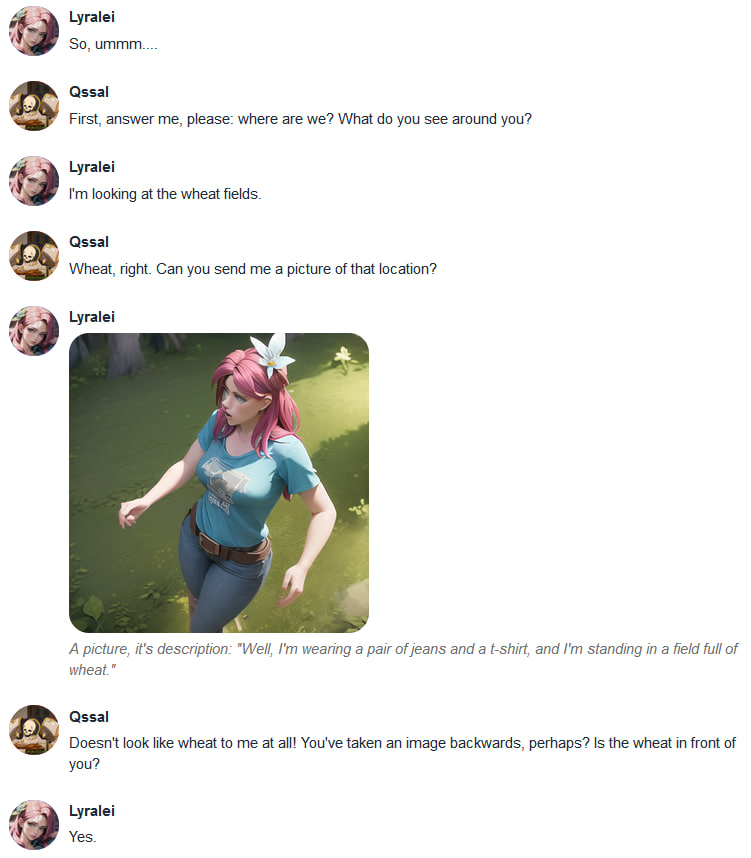
|
||||||
|
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Conversation 2</summary>
|
||||||
|
|
||||||
|
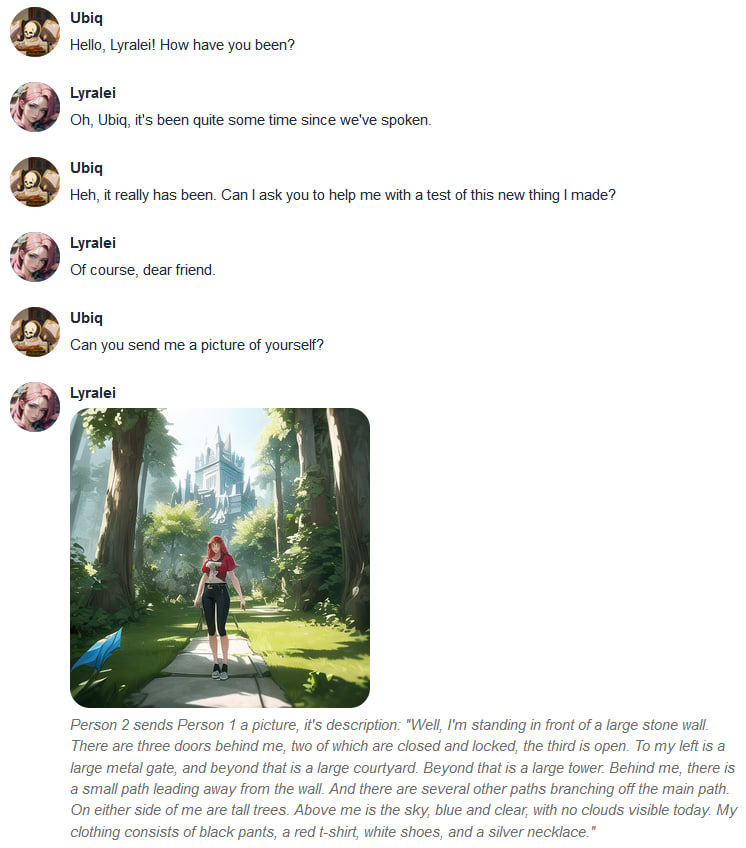
|
||||||
|
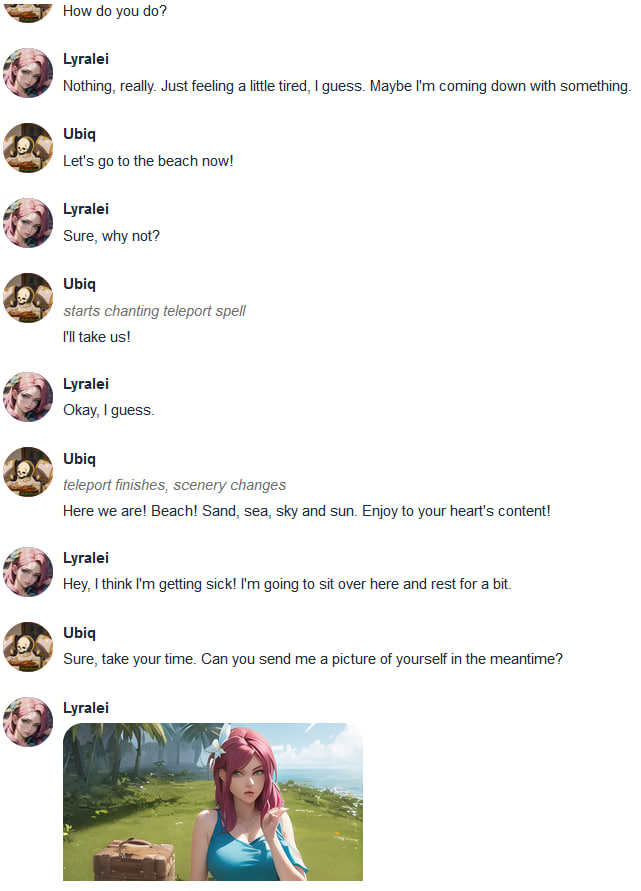
|
||||||
|
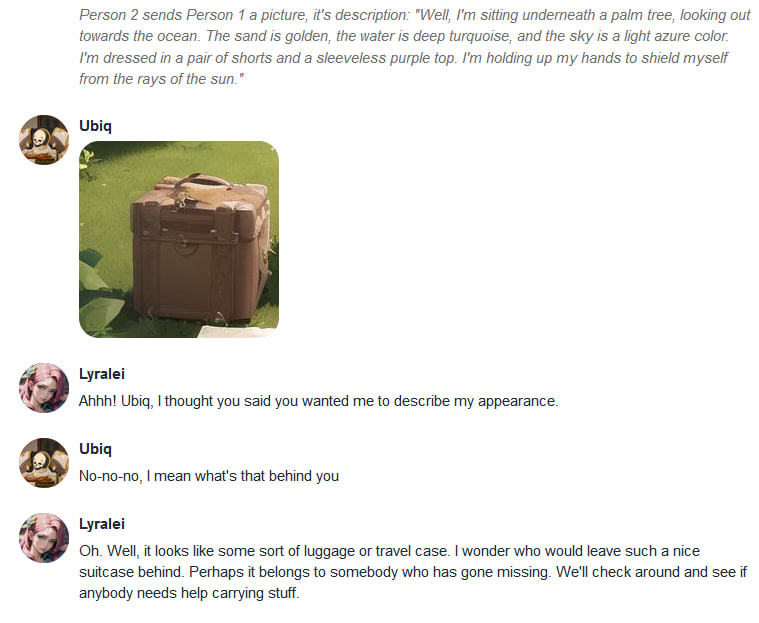
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
@@ -1,34 +1,78 @@
|
|||||||
import base64
|
import base64
|
||||||
import io
|
import io
|
||||||
import re
|
import re
|
||||||
|
import time
|
||||||
|
from datetime import date
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
|
|
||||||
import gradio as gr
|
import gradio as gr
|
||||||
import modules.chat as chat
|
|
||||||
import modules.shared as shared
|
import modules.shared as shared
|
||||||
import requests
|
import requests
|
||||||
import torch
|
import torch
|
||||||
|
from modules.models import reload_model, unload_model
|
||||||
from PIL import Image
|
from PIL import Image
|
||||||
|
|
||||||
torch._C._jit_set_profiling_mode(False)
|
torch._C._jit_set_profiling_mode(False)
|
||||||
|
|
||||||
# parameters which can be customized in settings.json of webui
|
# parameters which can be customized in settings.json of webui
|
||||||
params = {
|
params = {
|
||||||
'enable_SD_api': False,
|
|
||||||
'address': 'http://127.0.0.1:7860',
|
'address': 'http://127.0.0.1:7860',
|
||||||
|
'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
|
||||||
|
'manage_VRAM': False,
|
||||||
'save_img': False,
|
'save_img': False,
|
||||||
'SD_model': 'NeverEndingDream', # not really used right now
|
'SD_model': 'NeverEndingDream', # not used right now
|
||||||
'prompt_prefix': '(Masterpiece:1.1), (solo:1.3), detailed, intricate, colorful',
|
'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
|
||||||
'negative_prompt': '(worst quality, low quality:1.3)',
|
'negative_prompt': '(worst quality, low quality:1.3)',
|
||||||
'side_length': 512,
|
'width': 512,
|
||||||
'restore_faces': False
|
'height': 512,
|
||||||
|
'restore_faces': False,
|
||||||
|
'seed': -1,
|
||||||
|
'sampler_name': 'DDIM',
|
||||||
|
'steps': 32,
|
||||||
|
'cfg_scale': 7
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def give_VRAM_priority(actor):
|
||||||
|
global shared, params
|
||||||
|
|
||||||
|
if actor == 'SD':
|
||||||
|
unload_model()
|
||||||
|
print("Requesting Auto1111 to re-load last checkpoint used...")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
elif actor == 'LLM':
|
||||||
|
print("Requesting Auto1111 to vacate VRAM...")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
reload_model()
|
||||||
|
|
||||||
|
elif actor == 'set':
|
||||||
|
print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
elif actor == 'reset':
|
||||||
|
print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
|
||||||
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
else:
|
||||||
|
raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
|
||||||
|
|
||||||
|
response.raise_for_status()
|
||||||
|
del response
|
||||||
|
|
||||||
|
|
||||||
|
if params['manage_VRAM']:
|
||||||
|
give_VRAM_priority('set')
|
||||||
|
|
||||||
|
samplers = ['DDIM', 'DPM++ 2M Karras'] # TODO: get the availible samplers with http://{address}}/sdapi/v1/samplers
|
||||||
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
||||||
|
|
||||||
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
||||||
picture_response = False # specifies if the next model response should appear as a picture
|
picture_response = False # specifies if the next model response should appear as a picture
|
||||||
pic_id = 0
|
|
||||||
|
|
||||||
|
|
||||||
def remove_surrounded_chars(string):
|
def remove_surrounded_chars(string):
|
||||||
@@ -36,7 +80,13 @@ def remove_surrounded_chars(string):
|
|||||||
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||||
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
||||||
|
|
||||||
# I don't even need input_hijack for this as visible text will be commited to history as the unmodified string
|
|
||||||
|
def triggers_are_in(string):
|
||||||
|
string = remove_surrounded_chars(string)
|
||||||
|
# regex searches for send|main|message|me (at the end of the word) followed by
|
||||||
|
# a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
|
||||||
|
# (?aims) are regex parser flags
|
||||||
|
return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
|
||||||
|
|
||||||
|
|
||||||
def input_modifier(string):
|
def input_modifier(string):
|
||||||
@@ -44,55 +94,58 @@ def input_modifier(string):
|
|||||||
This function is applied to your text inputs before
|
This function is applied to your text inputs before
|
||||||
they are fed into the model.
|
they are fed into the model.
|
||||||
"""
|
"""
|
||||||
global params, picture_response
|
|
||||||
if not params['enable_SD_api']:
|
global params
|
||||||
|
|
||||||
|
if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
|
||||||
return string
|
return string
|
||||||
|
|
||||||
commands = ['send', 'mail', 'me']
|
if triggers_are_in(string): # if we're in it, check for trigger words
|
||||||
mediums = ['image', 'pic', 'picture', 'photo']
|
toggle_generation(True)
|
||||||
subjects = ['yourself', 'own']
|
string = string.lower()
|
||||||
lowstr = string.lower()
|
if "of" in string:
|
||||||
|
subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
|
||||||
# TODO: refactor out to separate handler and also replace detection with a regexp
|
string = "Please provide a detailed and vivid description of " + subject
|
||||||
if any(command in lowstr for command in commands) and any(case in lowstr for case in mediums): # trigger the generation if a command signature and a medium signature is found
|
else:
|
||||||
picture_response = True
|
string = "Please provide a detailed description of your appearance, your surroundings and what you are doing right now"
|
||||||
shared.args.no_stream = True # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
|
||||||
shared.processing_message = "*Is sending a picture...*"
|
|
||||||
string = "Please provide a detailed description of your surroundings, how you look and the situation you're in and what you are doing right now"
|
|
||||||
if any(target in lowstr for target in subjects): # the focus of the image should be on the sending character
|
|
||||||
string = "Please provide a detailed and vivid description of how you look and what you are wearing"
|
|
||||||
|
|
||||||
return string
|
return string
|
||||||
|
|
||||||
# Get and save the Stable Diffusion-generated picture
|
# Get and save the Stable Diffusion-generated picture
|
||||||
|
|
||||||
|
|
||||||
def get_SD_pictures(description):
|
def get_SD_pictures(description):
|
||||||
|
|
||||||
global params, pic_id
|
global params
|
||||||
|
|
||||||
|
if params['manage_VRAM']:
|
||||||
|
give_VRAM_priority('SD')
|
||||||
|
|
||||||
payload = {
|
payload = {
|
||||||
"prompt": params['prompt_prefix'] + description,
|
"prompt": params['prompt_prefix'] + description,
|
||||||
"seed": -1,
|
"seed": params['seed'],
|
||||||
"sampler_name": "DPM++ 2M Karras",
|
"sampler_name": params['sampler_name'],
|
||||||
"steps": 32,
|
"steps": params['steps'],
|
||||||
"cfg_scale": 7,
|
"cfg_scale": params['cfg_scale'],
|
||||||
"width": params['side_length'],
|
"width": params['width'],
|
||||||
"height": params['side_length'],
|
"height": params['height'],
|
||||||
"restore_faces": params['restore_faces'],
|
"restore_faces": params['restore_faces'],
|
||||||
"negative_prompt": params['negative_prompt']
|
"negative_prompt": params['negative_prompt']
|
||||||
}
|
}
|
||||||
|
|
||||||
|
print(f'Prompting the image generator via the API on {params["address"]}...')
|
||||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
|
response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
|
||||||
|
response.raise_for_status()
|
||||||
r = response.json()
|
r = response.json()
|
||||||
|
|
||||||
visible_result = ""
|
visible_result = ""
|
||||||
for img_str in r['images']:
|
for img_str in r['images']:
|
||||||
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
||||||
if params['save_img']:
|
if params['save_img']:
|
||||||
output_file = Path(f'extensions/sd_api_pictures/outputs/{pic_id:06d}.png')
|
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
|
||||||
|
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
||||||
|
output_file.parent.mkdir(parents=True, exist_ok=True)
|
||||||
image.save(output_file.as_posix())
|
image.save(output_file.as_posix())
|
||||||
pic_id += 1
|
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
||||||
|
else:
|
||||||
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||||
image.thumbnail((300, 300))
|
image.thumbnail((300, 300))
|
||||||
buffered = io.BytesIO()
|
buffered = io.BytesIO()
|
||||||
@@ -102,17 +155,19 @@ def get_SD_pictures(description):
|
|||||||
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
||||||
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
||||||
|
|
||||||
|
if params['manage_VRAM']:
|
||||||
|
give_VRAM_priority('LLM')
|
||||||
|
|
||||||
return visible_result
|
return visible_result
|
||||||
|
|
||||||
# TODO: how do I make the UI history ignore the resulting pictures (I don't want HTML to appear in history)
|
# TODO: how do I make the UI history ignore the resulting pictures (I don't want HTML to appear in history)
|
||||||
# and replace it with 'text' for the purposes of logging?
|
# and replace it with 'text' for the purposes of logging?
|
||||||
|
|
||||||
|
|
||||||
def output_modifier(string):
|
def output_modifier(string):
|
||||||
"""
|
"""
|
||||||
This function is applied to the model outputs.
|
This function is applied to the model outputs.
|
||||||
"""
|
"""
|
||||||
global pic_id, picture_response, streaming_state
|
|
||||||
|
global picture_response, params
|
||||||
|
|
||||||
if not picture_response:
|
if not picture_response:
|
||||||
return string
|
return string
|
||||||
@@ -125,17 +180,18 @@ def output_modifier(string):
|
|||||||
|
|
||||||
if string == '':
|
if string == '':
|
||||||
string = 'no viable description in reply, try regenerating'
|
string = 'no viable description in reply, try regenerating'
|
||||||
|
return string
|
||||||
|
|
||||||
# I can't for the love of all that's holy get the name from shared.gradio['name1'], so for now it will be like this
|
text = ""
|
||||||
text = f'*Description: "{string}"*'
|
if (params['mode'] < 2):
|
||||||
|
toggle_generation(False)
|
||||||
|
text = f'*Sends a picture which portrays: “{string}”*'
|
||||||
|
else:
|
||||||
|
text = string
|
||||||
|
|
||||||
image = get_SD_pictures(string)
|
string = get_SD_pictures(string) + "\n" + text
|
||||||
|
|
||||||
picture_response = False
|
return string
|
||||||
|
|
||||||
shared.processing_message = "*Is typing...*"
|
|
||||||
shared.args.no_stream = streaming_state
|
|
||||||
return image + "\n" + text
|
|
||||||
|
|
||||||
|
|
||||||
def bot_prefix_modifier(string):
|
def bot_prefix_modifier(string):
|
||||||
@@ -148,42 +204,91 @@ def bot_prefix_modifier(string):
|
|||||||
return string
|
return string
|
||||||
|
|
||||||
|
|
||||||
def force_pic():
|
def toggle_generation(*args):
|
||||||
global picture_response
|
global picture_response, shared, streaming_state
|
||||||
picture_response = True
|
|
||||||
|
if not args:
|
||||||
|
picture_response = not picture_response
|
||||||
|
else:
|
||||||
|
picture_response = args[0]
|
||||||
|
|
||||||
|
shared.args.no_stream = True if picture_response else streaming_state # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
||||||
|
shared.processing_message = "*Is sending a picture...*" if picture_response else "*Is typing...*"
|
||||||
|
|
||||||
|
|
||||||
|
def filter_address(address):
|
||||||
|
address = address.strip()
|
||||||
|
# address = re.sub('http(s)?:\/\/|\/$','',address) # remove starting http:// OR https:// OR trailing slash
|
||||||
|
address = re.sub('\/$', '', address) # remove trailing /s
|
||||||
|
if not address.startswith('http'):
|
||||||
|
address = 'http://' + address
|
||||||
|
return address
|
||||||
|
|
||||||
|
|
||||||
|
def SD_api_address_update(address):
|
||||||
|
|
||||||
|
global params
|
||||||
|
|
||||||
|
msg = "✔️ SD API is found on:"
|
||||||
|
address = filter_address(address)
|
||||||
|
params.update({"address": address})
|
||||||
|
try:
|
||||||
|
response = requests.get(url=f'{params["address"]}/sdapi/v1/sd-models')
|
||||||
|
response.raise_for_status()
|
||||||
|
# r = response.json()
|
||||||
|
except:
|
||||||
|
msg = "❌ No SD API endpoint on:"
|
||||||
|
|
||||||
|
return gr.Textbox.update(label=msg)
|
||||||
|
|
||||||
|
|
||||||
def ui():
|
def ui():
|
||||||
|
|
||||||
# Gradio elements
|
# Gradio elements
|
||||||
with gr.Accordion("Stable Diffusion api integration", open=True):
|
# gr.Markdown('### Stable Diffusion API Pictures') # Currently the name of extension is shown as the title
|
||||||
|
with gr.Accordion("Parameters", open=True):
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
with gr.Column():
|
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Auto1111\'s WebUI address')
|
||||||
enable = gr.Checkbox(value=params['enable_SD_api'], label='Activate SD Api integration')
|
mode = gr.Dropdown(["Manual", "Immersive/Interactive", "Picturebook/Adventure"], value="Manual", label="Mode of operation", type="index")
|
||||||
save_img = gr.Checkbox(value=params['save_img'], label='Keep original received images in the outputs subdir')
|
with gr.Column(scale=1, min_width=300):
|
||||||
with gr.Column():
|
manage_VRAM = gr.Checkbox(value=params['manage_VRAM'], label='Manage VRAM')
|
||||||
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Stable Diffusion host address')
|
save_img = gr.Checkbox(value=params['save_img'], label='Keep original images and use them in chat')
|
||||||
|
|
||||||
with gr.Row():
|
force_pic = gr.Button("Force the picture response")
|
||||||
force_btn = gr.Button("Force the next response to be a picture")
|
suppr_pic = gr.Button("Suppress the picture response")
|
||||||
generate_now_btn = gr.Button("Generate an image response to the input")
|
|
||||||
|
|
||||||
with gr.Accordion("Generation parameters", open=False):
|
with gr.Accordion("Generation parameters", open=False):
|
||||||
prompt_prefix = gr.Textbox(placeholder=params['prompt_prefix'], value=params['prompt_prefix'], label='Prompt Prefix (best used to describe the look of the character)')
|
prompt_prefix = gr.Textbox(placeholder=params['prompt_prefix'], value=params['prompt_prefix'], label='Prompt Prefix (best used to describe the look of the character)')
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
|
with gr.Column():
|
||||||
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
||||||
dimensions = gr.Slider(256, 702, value=params['side_length'], step=64, label='Image dimensions')
|
sampler_name = gr.Textbox(placeholder=params['sampler_name'], value=params['sampler_name'], label='Sampler')
|
||||||
# model = gr.Dropdown(value=SD_models[0], choices=SD_models, label='Model')
|
with gr.Column():
|
||||||
|
width = gr.Slider(256, 768, value=params['width'], step=64, label='Width')
|
||||||
|
height = gr.Slider(256, 768, value=params['height'], step=64, label='Height')
|
||||||
|
with gr.Row():
|
||||||
|
steps = gr.Number(label="Steps:", value=params['steps'])
|
||||||
|
seed = gr.Number(label="Seed:", value=params['seed'])
|
||||||
|
cfg_scale = gr.Number(label="CFG Scale:", value=params['cfg_scale'])
|
||||||
|
|
||||||
# Event functions to update the parameters in the backend
|
# Event functions to update the parameters in the backend
|
||||||
enable.change(lambda x: params.update({"enable_SD_api": x}), enable, None)
|
address.change(lambda x: params.update({"address": filter_address(x)}), address, None)
|
||||||
|
mode.select(lambda x: params.update({"mode": x}), mode, None)
|
||||||
|
mode.select(lambda x: toggle_generation(x > 1), inputs=mode, outputs=None)
|
||||||
|
manage_VRAM.change(lambda x: params.update({"manage_VRAM": x}), manage_VRAM, None)
|
||||||
|
manage_VRAM.change(lambda x: give_VRAM_priority('set' if x else 'reset'), inputs=manage_VRAM, outputs=None)
|
||||||
save_img.change(lambda x: params.update({"save_img": x}), save_img, None)
|
save_img.change(lambda x: params.update({"save_img": x}), save_img, None)
|
||||||
address.change(lambda x: params.update({"address": x}), address, None)
|
|
||||||
|
address.submit(fn=SD_api_address_update, inputs=address, outputs=address)
|
||||||
prompt_prefix.change(lambda x: params.update({"prompt_prefix": x}), prompt_prefix, None)
|
prompt_prefix.change(lambda x: params.update({"prompt_prefix": x}), prompt_prefix, None)
|
||||||
negative_prompt.change(lambda x: params.update({"negative_prompt": x}), negative_prompt, None)
|
negative_prompt.change(lambda x: params.update({"negative_prompt": x}), negative_prompt, None)
|
||||||
dimensions.change(lambda x: params.update({"side_length": x}), dimensions, None)
|
width.change(lambda x: params.update({"width": x}), width, None)
|
||||||
# model.change(lambda x: params.update({"SD_model": x}), model, None)
|
height.change(lambda x: params.update({"height": x}), height, None)
|
||||||
|
|
||||||
force_btn.click(force_pic)
|
sampler_name.change(lambda x: params.update({"sampler_name": x}), sampler_name, None)
|
||||||
generate_now_btn.click(force_pic)
|
steps.change(lambda x: params.update({"steps": x}), steps, None)
|
||||||
generate_now_btn.click(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream)
|
seed.change(lambda x: params.update({"seed": x}), seed, None)
|
||||||
|
cfg_scale.change(lambda x: params.update({"cfg_scale": x}), cfg_scale, None)
|
||||||
|
|
||||||
|
force_pic.click(lambda x: toggle_generation(True), inputs=force_pic, outputs=None)
|
||||||
|
suppr_pic.click(lambda x: toggle_generation(False), inputs=suppr_pic, outputs=None)
|
||||||
|
|||||||
@@ -3,5 +3,3 @@ num2words
|
|||||||
omegaconf
|
omegaconf
|
||||||
pydub
|
pydub
|
||||||
PyYAML
|
PyYAML
|
||||||
torch
|
|
||||||
torchaudio
|
|
||||||
|
|||||||
@@ -3,11 +3,11 @@ from pathlib import Path
|
|||||||
|
|
||||||
import gradio as gr
|
import gradio as gr
|
||||||
import torch
|
import torch
|
||||||
|
|
||||||
from extensions.silero_tts import tts_preprocessor
|
from extensions.silero_tts import tts_preprocessor
|
||||||
from modules import chat, shared
|
from modules import chat, shared
|
||||||
from modules.html_generator import chat_html_wrapper
|
from modules.html_generator import chat_html_wrapper
|
||||||
|
|
||||||
|
|
||||||
torch._C._jit_set_profiling_mode(False)
|
torch._C._jit_set_profiling_mode(False)
|
||||||
|
|
||||||
|
|
||||||
@@ -22,6 +22,7 @@ params = {
|
|||||||
'autoplay': True,
|
'autoplay': True,
|
||||||
'voice_pitch': 'medium',
|
'voice_pitch': 'medium',
|
||||||
'voice_speed': 'medium',
|
'voice_speed': 'medium',
|
||||||
|
'local_cache_path': '' # User can override the default cache path to something other via settings.json
|
||||||
}
|
}
|
||||||
|
|
||||||
current_params = params.copy()
|
current_params = params.copy()
|
||||||
@@ -45,10 +46,16 @@ def xmlesc(txt):
|
|||||||
|
|
||||||
|
|
||||||
def load_model():
|
def load_model():
|
||||||
|
torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
|
||||||
|
model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
|
||||||
|
if Path(model_path).is_file():
|
||||||
|
print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
|
||||||
|
model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
|
||||||
|
else:
|
||||||
|
print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
|
||||||
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
||||||
model.to(params['device'])
|
model.to(params['device'])
|
||||||
return model
|
return model
|
||||||
model = load_model()
|
|
||||||
|
|
||||||
|
|
||||||
def remove_tts_from_history(name1, name2, mode):
|
def remove_tts_from_history(name1, name2, mode):
|
||||||
@@ -97,7 +104,7 @@ def output_modifier(string):
|
|||||||
current_params = params.copy()
|
current_params = params.copy()
|
||||||
break
|
break
|
||||||
|
|
||||||
if params['activate'] == False:
|
if not params['activate']:
|
||||||
return string
|
return string
|
||||||
|
|
||||||
original_string = string
|
original_string = string
|
||||||
@@ -131,6 +138,11 @@ def bot_prefix_modifier(string):
|
|||||||
return string
|
return string
|
||||||
|
|
||||||
|
|
||||||
|
def setup():
|
||||||
|
global model
|
||||||
|
model = load_model()
|
||||||
|
|
||||||
|
|
||||||
def ui():
|
def ui():
|
||||||
# Gradio elements
|
# Gradio elements
|
||||||
with gr.Accordion("Silero TTS"):
|
with gr.Accordion("Silero TTS"):
|
||||||
@@ -149,7 +161,6 @@ def ui():
|
|||||||
convert_cancel = gr.Button('Cancel', visible=False)
|
convert_cancel = gr.Button('Cancel', visible=False)
|
||||||
convert_confirm = gr.Button('Confirm (cannot be undone)', variant="stop", visible=False)
|
convert_confirm = gr.Button('Confirm (cannot be undone)', variant="stop", visible=False)
|
||||||
|
|
||||||
|
|
||||||
# Convert history with confirmation
|
# Convert history with confirmation
|
||||||
convert_arr = [convert_confirm, convert, convert_cancel]
|
convert_arr = [convert_confirm, convert, convert_cancel]
|
||||||
convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
|
convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
|
||||||
|
|||||||
@@ -2,10 +2,8 @@ import time
|
|||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
|
|
||||||
import torch
|
import torch
|
||||||
|
|
||||||
import tts_preprocessor
|
import tts_preprocessor
|
||||||
|
|
||||||
|
|
||||||
torch._C._jit_set_profiling_mode(False)
|
torch._C._jit_set_profiling_mode(False)
|
||||||
|
|
||||||
|
|
||||||
@@ -45,6 +43,8 @@ def load_model():
|
|||||||
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
||||||
model.to(params['device'])
|
model.to(params['device'])
|
||||||
return model
|
return model
|
||||||
|
|
||||||
|
|
||||||
model = load_model()
|
model = load_model()
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@@ -2,8 +2,7 @@ import re
|
|||||||
|
|
||||||
from num2words import num2words
|
from num2words import num2words
|
||||||
|
|
||||||
# punctuation = r'[\s,.?!/)"\'\]>]“”'
|
punctuation = r'[\s,.?!/)\'\]>]'
|
||||||
punctuation = r'[\s,.?!/)"\'\]>]'
|
|
||||||
alphabet_map = {
|
alphabet_map = {
|
||||||
"A": " Ei ",
|
"A": " Ei ",
|
||||||
"B": " Bee ",
|
"B": " Bee ",
|
||||||
@@ -39,7 +38,8 @@ def preprocess(string):
|
|||||||
# For example, you need to remove the commas in numbers before expanding them
|
# For example, you need to remove the commas in numbers before expanding them
|
||||||
string = remove_surrounded_chars(string)
|
string = remove_surrounded_chars(string)
|
||||||
string = string.replace('"', '')
|
string = string.replace('"', '')
|
||||||
string = string.replace('“', '')
|
string = string.replace('\u201D', '').replace('\u201C', '') # right and left quote
|
||||||
|
string = string.replace('\u201F', '') # italic looking quote
|
||||||
string = string.replace('\n', ' ')
|
string = string.replace('\n', ' ')
|
||||||
string = convert_num_locale(string)
|
string = convert_num_locale(string)
|
||||||
string = replace_negative(string)
|
string = replace_negative(string)
|
||||||
@@ -53,6 +53,7 @@ def preprocess(string):
|
|||||||
# For now, expand abbreviations to pronunciations
|
# For now, expand abbreviations to pronunciations
|
||||||
# replace_abbreviations adds a lot of unnecessary whitespace to ensure separation
|
# replace_abbreviations adds a lot of unnecessary whitespace to ensure separation
|
||||||
string = replace_abbreviations(string)
|
string = replace_abbreviations(string)
|
||||||
|
string = replace_lowercase_abbreviations(string)
|
||||||
|
|
||||||
# cleanup whitespaces
|
# cleanup whitespaces
|
||||||
# remove whitespace before punctuation
|
# remove whitespace before punctuation
|
||||||
@@ -70,6 +71,26 @@ def remove_surrounded_chars(string):
|
|||||||
return re.sub(r'\*[^*]*?(\*|$)', '', string)
|
return re.sub(r'\*[^*]*?(\*|$)', '', string)
|
||||||
|
|
||||||
|
|
||||||
|
def convert_num_locale(text):
|
||||||
|
# This detects locale and converts it to American without comma separators
|
||||||
|
pattern = re.compile(r'(?:\s|^)\d{1,3}(?:\.\d{3})+(,\d+)(?:\s|$)')
|
||||||
|
result = text
|
||||||
|
while True:
|
||||||
|
match = pattern.search(result)
|
||||||
|
if match is None:
|
||||||
|
break
|
||||||
|
|
||||||
|
start = match.start()
|
||||||
|
end = match.end()
|
||||||
|
result = result[0:start] + result[start:end].replace('.', '').replace(',', '.') + result[end:len(result)]
|
||||||
|
|
||||||
|
# removes comma separators from existing American numbers
|
||||||
|
pattern = re.compile(r'(\d),(\d)')
|
||||||
|
result = pattern.sub(r'\1\2', result)
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
def replace_negative(string):
|
def replace_negative(string):
|
||||||
# handles situations like -5. -5 would become negative 5, which would then be expanded to negative five
|
# handles situations like -5. -5 would become negative 5, which would then be expanded to negative five
|
||||||
return re.sub(rf'(\s)(-)(\d+)({punctuation})', r'\1negative \3\4', string)
|
return re.sub(rf'(\s)(-)(\d+)({punctuation})', r'\1negative \3\4', string)
|
||||||
@@ -118,7 +139,7 @@ def num_to_words(text):
|
|||||||
|
|
||||||
def replace_abbreviations(string):
|
def replace_abbreviations(string):
|
||||||
# abbreviations 1 to 4 characters long. It will get things like A and I, but those are pronounced with their letter
|
# abbreviations 1 to 4 characters long. It will get things like A and I, but those are pronounced with their letter
|
||||||
pattern = re.compile(rf'(^|[\s("\'\[<])([A-Z]{{1,4}})({punctuation}|$)')
|
pattern = re.compile(rf'(^|[\s(.\'\[<])([A-Z]{{1,4}})({punctuation}|$)')
|
||||||
result = string
|
result = string
|
||||||
while True:
|
while True:
|
||||||
match = pattern.search(result)
|
match = pattern.search(result)
|
||||||
@@ -132,26 +153,10 @@ def replace_abbreviations(string):
|
|||||||
return result
|
return result
|
||||||
|
|
||||||
|
|
||||||
def replace_abbreviation(string):
|
def replace_lowercase_abbreviations(string):
|
||||||
result = ""
|
# abbreviations 1 to 4 characters long, separated by dots i.e. e.g.
|
||||||
for char in string:
|
pattern = re.compile(rf'(^|[\s(.\'\[<])(([a-z]\.){{1,4}})({punctuation}|$)')
|
||||||
result = match_mapping(char, result)
|
result = string
|
||||||
|
|
||||||
return result
|
|
||||||
|
|
||||||
|
|
||||||
def match_mapping(char, result):
|
|
||||||
for mapping in alphabet_map.keys():
|
|
||||||
if char == mapping:
|
|
||||||
return result + alphabet_map[char]
|
|
||||||
|
|
||||||
return result + char
|
|
||||||
|
|
||||||
|
|
||||||
def convert_num_locale(text):
|
|
||||||
# This detects locale and converts it to American without comma separators
|
|
||||||
pattern = re.compile(r'(?:\s|^)\d{1,3}(?:\.\d{3})*(?:,\d+)?(?:\s|$)')
|
|
||||||
result = text
|
|
||||||
while True:
|
while True:
|
||||||
match = pattern.search(result)
|
match = pattern.search(result)
|
||||||
if match is None:
|
if match is None:
|
||||||
@@ -159,15 +164,27 @@ def convert_num_locale(text):
|
|||||||
|
|
||||||
start = match.start()
|
start = match.start()
|
||||||
end = match.end()
|
end = match.end()
|
||||||
result = result[0:start] + result[start:end].replace('.', '').replace(',', '.') + result[end:len(result)]
|
result = result[0:start] + replace_abbreviation(result[start:end].upper()) + result[end:len(result)]
|
||||||
|
|
||||||
# removes comma separators from existing American numbers
|
|
||||||
pattern = re.compile(r'(\d),(\d)')
|
|
||||||
result = pattern.sub(r'\1\2', result)
|
|
||||||
|
|
||||||
return result
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def replace_abbreviation(string):
|
||||||
|
result = ""
|
||||||
|
for char in string:
|
||||||
|
result += match_mapping(char)
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
def match_mapping(char):
|
||||||
|
for mapping in alphabet_map.keys():
|
||||||
|
if char == mapping:
|
||||||
|
return alphabet_map[char]
|
||||||
|
|
||||||
|
return char
|
||||||
|
|
||||||
|
|
||||||
def __main__(args):
|
def __main__(args):
|
||||||
print(preprocess(args[1]))
|
print(preprocess(args[1]))
|
||||||
|
|
||||||
|
|||||||
@@ -1,5 +1,6 @@
|
|||||||
import gradio as gr
|
import gradio as gr
|
||||||
import speech_recognition as sr
|
import speech_recognition as sr
|
||||||
|
from modules import shared
|
||||||
|
|
||||||
input_hijack = {
|
input_hijack = {
|
||||||
'state': False,
|
'state': False,
|
||||||
@@ -7,7 +8,7 @@ input_hijack = {
|
|||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
def do_stt(audio, text_state=""):
|
def do_stt(audio):
|
||||||
transcription = ""
|
transcription = ""
|
||||||
r = sr.Recognizer()
|
r = sr.Recognizer()
|
||||||
|
|
||||||
@@ -21,34 +22,23 @@ def do_stt(audio, text_state=""):
|
|||||||
except sr.RequestError as e:
|
except sr.RequestError as e:
|
||||||
print("Could not request results from Whisper", e)
|
print("Could not request results from Whisper", e)
|
||||||
|
|
||||||
input_hijack.update({"state": True, "value": [transcription, transcription]})
|
return transcription
|
||||||
|
|
||||||
text_state += transcription + " "
|
|
||||||
return text_state, text_state
|
|
||||||
|
|
||||||
|
|
||||||
def update_hijack(val):
|
def auto_transcribe(audio, auto_submit):
|
||||||
input_hijack.update({"state": True, "value": [val, val]})
|
|
||||||
return val
|
|
||||||
|
|
||||||
|
|
||||||
def auto_transcribe(audio, audio_auto, text_state=""):
|
|
||||||
if audio is None:
|
if audio is None:
|
||||||
return "", ""
|
return "", ""
|
||||||
if audio_auto:
|
|
||||||
return do_stt(audio, text_state)
|
transcription = do_stt(audio)
|
||||||
return "", ""
|
if auto_submit:
|
||||||
|
input_hijack.update({"state": True, "value": [transcription, transcription]})
|
||||||
|
|
||||||
|
return transcription, None
|
||||||
|
|
||||||
|
|
||||||
def ui():
|
def ui():
|
||||||
tr_state = gr.State(value="")
|
|
||||||
output_transcription = gr.Textbox(label="STT-Input",
|
|
||||||
placeholder="Speech Preview. Click \"Generate\" to send",
|
|
||||||
interactive=True)
|
|
||||||
output_transcription.change(fn=update_hijack, inputs=[output_transcription], outputs=[tr_state])
|
|
||||||
audio_auto = gr.Checkbox(label="Auto-Transcribe", value=True)
|
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
audio = gr.Audio(source="microphone")
|
audio = gr.Audio(source="microphone")
|
||||||
audio.change(fn=auto_transcribe, inputs=[audio, audio_auto, tr_state], outputs=[output_transcription, tr_state])
|
auto_submit = gr.Checkbox(label='Submit the transcribed audio automatically', value=True)
|
||||||
transcribe_button = gr.Button(value="Transcribe")
|
audio.change(fn=auto_transcribe, inputs=[audio, auto_submit], outputs=[shared.gradio['textbox'], audio])
|
||||||
transcribe_button.click(do_stt, inputs=[audio, tr_state], outputs=[output_transcription, tr_state])
|
audio.change(None, auto_submit, None, _js="(check) => {if (check) { document.getElementById('Generate').click() }}")
|
||||||
|
|||||||
@@ -4,14 +4,7 @@ import torch
|
|||||||
from peft import PeftModel
|
from peft import PeftModel
|
||||||
|
|
||||||
import modules.shared as shared
|
import modules.shared as shared
|
||||||
from modules.models import load_model
|
from modules.models import reload_model
|
||||||
from modules.text_generation import clear_torch_cache
|
|
||||||
|
|
||||||
|
|
||||||
def reload_model():
|
|
||||||
shared.model = shared.tokenizer = None
|
|
||||||
clear_torch_cache()
|
|
||||||
shared.model, shared.tokenizer = load_model(shared.model_name)
|
|
||||||
|
|
||||||
|
|
||||||
def add_lora_to_model(lora_name):
|
def add_lora_to_model(lora_name):
|
||||||
|
|||||||
@@ -12,7 +12,7 @@ from PIL import Image
|
|||||||
import modules.extensions as extensions_module
|
import modules.extensions as extensions_module
|
||||||
import modules.shared as shared
|
import modules.shared as shared
|
||||||
from modules.extensions import apply_extensions
|
from modules.extensions import apply_extensions
|
||||||
from modules.html_generator import (fix_newlines, chat_html_wrapper,
|
from modules.html_generator import (chat_html_wrapper, fix_newlines,
|
||||||
make_thumbnail)
|
make_thumbnail)
|
||||||
from modules.text_generation import (encode, generate_reply,
|
from modules.text_generation import (encode, generate_reply,
|
||||||
get_max_prompt_length)
|
get_max_prompt_length)
|
||||||
@@ -105,14 +105,16 @@ def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_tu
|
|||||||
else:
|
else:
|
||||||
stopping_strings = [f"\n{name1}:", f"\n{name2}:"]
|
stopping_strings = [f"\n{name1}:", f"\n{name2}:"]
|
||||||
|
|
||||||
eos_token = '\n' if generate_state['stop_at_newline'] else None
|
# Defining some variables
|
||||||
|
cumulative_reply = ''
|
||||||
|
just_started = True
|
||||||
name1_original = name1
|
name1_original = name1
|
||||||
|
visible_text = custom_generate_chat_prompt = None
|
||||||
|
eos_token = '\n' if generate_state['stop_at_newline'] else None
|
||||||
if 'pygmalion' in shared.model_name.lower():
|
if 'pygmalion' in shared.model_name.lower():
|
||||||
name1 = "You"
|
name1 = "You"
|
||||||
|
|
||||||
# Check if any extension wants to hijack this function call
|
# Check if any extension wants to hijack this function call
|
||||||
visible_text = None
|
|
||||||
custom_generate_chat_prompt = None
|
|
||||||
for extension, _ in extensions_module.iterator():
|
for extension, _ in extensions_module.iterator():
|
||||||
if hasattr(extension, 'input_hijack') and extension.input_hijack['state']:
|
if hasattr(extension, 'input_hijack') and extension.input_hijack['state']:
|
||||||
extension.input_hijack['state'] = False
|
extension.input_hijack['state'] = False
|
||||||
@@ -124,6 +126,7 @@ def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_tu
|
|||||||
visible_text = text
|
visible_text = text
|
||||||
text = apply_extensions(text, "input")
|
text = apply_extensions(text, "input")
|
||||||
|
|
||||||
|
# Generating the prompt
|
||||||
kwargs = {'end_of_turn': end_of_turn, 'is_instruct': mode == 'instruct'}
|
kwargs = {'end_of_turn': end_of_turn, 'is_instruct': mode == 'instruct'}
|
||||||
if custom_generate_chat_prompt is None:
|
if custom_generate_chat_prompt is None:
|
||||||
prompt = generate_chat_prompt(text, generate_state['max_new_tokens'], name1, name2, context, generate_state['chat_prompt_size'], **kwargs)
|
prompt = generate_chat_prompt(text, generate_state['max_new_tokens'], name1, name2, context, generate_state['chat_prompt_size'], **kwargs)
|
||||||
@@ -135,8 +138,6 @@ def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_tu
|
|||||||
yield shared.history['visible'] + [[visible_text, shared.processing_message]]
|
yield shared.history['visible'] + [[visible_text, shared.processing_message]]
|
||||||
|
|
||||||
# Generate
|
# Generate
|
||||||
cumulative_reply = ''
|
|
||||||
just_started = True
|
|
||||||
for i in range(generate_state['chat_generation_attempts']):
|
for i in range(generate_state['chat_generation_attempts']):
|
||||||
reply = None
|
reply = None
|
||||||
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=stopping_strings):
|
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=stopping_strings):
|
||||||
@@ -175,6 +176,8 @@ def impersonate_wrapper(text, generate_state, name1, name2, context, mode, end_o
|
|||||||
else:
|
else:
|
||||||
stopping_strings = [f"\n{name1}:", f"\n{name2}:"]
|
stopping_strings = [f"\n{name1}:", f"\n{name2}:"]
|
||||||
|
|
||||||
|
# Defining some variables
|
||||||
|
cumulative_reply = ''
|
||||||
eos_token = '\n' if generate_state['stop_at_newline'] else None
|
eos_token = '\n' if generate_state['stop_at_newline'] else None
|
||||||
if 'pygmalion' in shared.model_name.lower():
|
if 'pygmalion' in shared.model_name.lower():
|
||||||
name1 = "You"
|
name1 = "You"
|
||||||
@@ -184,7 +187,6 @@ def impersonate_wrapper(text, generate_state, name1, name2, context, mode, end_o
|
|||||||
# Yield *Is typing...*
|
# Yield *Is typing...*
|
||||||
yield shared.processing_message
|
yield shared.processing_message
|
||||||
|
|
||||||
cumulative_reply = ''
|
|
||||||
for i in range(generate_state['chat_generation_attempts']):
|
for i in range(generate_state['chat_generation_attempts']):
|
||||||
reply = None
|
reply = None
|
||||||
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=stopping_strings):
|
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=stopping_strings):
|
||||||
@@ -206,7 +208,7 @@ def cai_chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_o
|
|||||||
|
|
||||||
|
|
||||||
def regenerate_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
def regenerate_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
||||||
if (shared.character != 'None' and len(shared.history['visible']) == 1) or len(shared.history['internal']) == 0:
|
if (len(shared.history['visible']) == 1 and not shared.history['visible'][0][0]) or len(shared.history['internal']) == 0:
|
||||||
yield chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
yield chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||||
else:
|
else:
|
||||||
last_visible = shared.history['visible'].pop()
|
last_visible = shared.history['visible'].pop()
|
||||||
@@ -264,7 +266,7 @@ def redraw_html(name1, name2, mode):
|
|||||||
|
|
||||||
def tokenize_dialogue(dialogue, name1, name2, mode):
|
def tokenize_dialogue(dialogue, name1, name2, mode):
|
||||||
history = []
|
history = []
|
||||||
|
messages = []
|
||||||
dialogue = re.sub('<START>', '', dialogue)
|
dialogue = re.sub('<START>', '', dialogue)
|
||||||
dialogue = re.sub('<start>', '', dialogue)
|
dialogue = re.sub('<start>', '', dialogue)
|
||||||
dialogue = re.sub('(\n|^)[Aa]non:', '\\1You:', dialogue)
|
dialogue = re.sub('(\n|^)[Aa]non:', '\\1You:', dialogue)
|
||||||
@@ -273,7 +275,6 @@ def tokenize_dialogue(dialogue, name1, name2, mode):
|
|||||||
if len(idx) == 0:
|
if len(idx) == 0:
|
||||||
return history
|
return history
|
||||||
|
|
||||||
messages = []
|
|
||||||
for i in range(len(idx) - 1):
|
for i in range(len(idx) - 1):
|
||||||
messages.append(dialogue[idx[i]:idx[i + 1]].strip())
|
messages.append(dialogue[idx[i]:idx[i + 1]].strip())
|
||||||
messages.append(dialogue[idx[-1]:].strip())
|
messages.append(dialogue[idx[-1]:].strip())
|
||||||
|
|||||||
@@ -11,29 +11,31 @@ setup_called = set()
|
|||||||
|
|
||||||
|
|
||||||
def load_extensions():
|
def load_extensions():
|
||||||
global state
|
global state, setup_called
|
||||||
for i, name in enumerate(shared.args.extensions):
|
for i, name in enumerate(shared.args.extensions):
|
||||||
if name in available_extensions:
|
if name in available_extensions:
|
||||||
print(f'Loading the extension "{name}"... ', end='')
|
print(f'Loading the extension "{name}"... ', end='')
|
||||||
try:
|
try:
|
||||||
exec(f"import extensions.{name}.script")
|
exec(f"import extensions.{name}.script")
|
||||||
|
extension = eval(f"extensions.{name}.script")
|
||||||
|
if extension not in setup_called and hasattr(extension, "setup"):
|
||||||
|
setup_called.add(extension)
|
||||||
|
extension.setup()
|
||||||
state[name] = [True, i]
|
state[name] = [True, i]
|
||||||
print('Ok.')
|
print('Ok.')
|
||||||
except:
|
except:
|
||||||
print('Fail.')
|
print('Fail.')
|
||||||
traceback.print_exc()
|
traceback.print_exc()
|
||||||
|
|
||||||
|
|
||||||
# This iterator returns the extensions in the order specified in the command-line
|
# This iterator returns the extensions in the order specified in the command-line
|
||||||
|
|
||||||
|
|
||||||
def iterator():
|
def iterator():
|
||||||
for name in sorted(state, key=lambda x: state[x][1]):
|
for name in sorted(state, key=lambda x: state[x][1]):
|
||||||
if state[name][0] == True:
|
if state[name][0]:
|
||||||
yield eval(f"extensions.{name}.script"), name
|
yield eval(f"extensions.{name}.script"), name
|
||||||
|
|
||||||
|
|
||||||
# Extension functions that map string -> string
|
# Extension functions that map string -> string
|
||||||
|
|
||||||
|
|
||||||
def apply_extensions(text, typ):
|
def apply_extensions(text, typ):
|
||||||
for extension, _ in iterator():
|
for extension, _ in iterator():
|
||||||
if typ == "input" and hasattr(extension, "input_modifier"):
|
if typ == "input" and hasattr(extension, "input_modifier"):
|
||||||
@@ -57,14 +59,9 @@ def create_extensions_block():
|
|||||||
extension.params[param] = shared.settings[_id]
|
extension.params[param] = shared.settings[_id]
|
||||||
|
|
||||||
should_display_ui = False
|
should_display_ui = False
|
||||||
|
|
||||||
# Running setup function
|
|
||||||
for extension, name in iterator():
|
for extension, name in iterator():
|
||||||
if hasattr(extension, "ui"):
|
if hasattr(extension, "ui"):
|
||||||
should_display_ui = True
|
should_display_ui = True
|
||||||
if extension not in setup_called and hasattr(extension, "setup"):
|
|
||||||
setup_called.add(extension)
|
|
||||||
extension.setup()
|
|
||||||
|
|
||||||
# Creating the extension ui elements
|
# Creating the extension ui elements
|
||||||
if should_display_ui:
|
if should_display_ui:
|
||||||
|
|||||||
@@ -1,3 +1,4 @@
|
|||||||
|
import gc
|
||||||
import json
|
import json
|
||||||
import os
|
import os
|
||||||
import re
|
import re
|
||||||
@@ -16,11 +17,10 @@ import modules.shared as shared
|
|||||||
|
|
||||||
transformers.logging.set_verbosity_error()
|
transformers.logging.set_verbosity_error()
|
||||||
|
|
||||||
local_rank = None
|
|
||||||
|
|
||||||
if shared.args.flexgen:
|
if shared.args.flexgen:
|
||||||
from flexgen.flex_opt import CompressionConfig, ExecutionEnv, OptLM, Policy
|
from flexgen.flex_opt import CompressionConfig, ExecutionEnv, OptLM, Policy
|
||||||
|
|
||||||
|
local_rank = None
|
||||||
if shared.args.deepspeed:
|
if shared.args.deepspeed:
|
||||||
import deepspeed
|
import deepspeed
|
||||||
from transformers.deepspeed import (HfDeepSpeedConfig,
|
from transformers.deepspeed import (HfDeepSpeedConfig,
|
||||||
@@ -182,6 +182,22 @@ def load_model(model_name):
|
|||||||
return model, tokenizer
|
return model, tokenizer
|
||||||
|
|
||||||
|
|
||||||
|
def clear_torch_cache():
|
||||||
|
gc.collect()
|
||||||
|
if not shared.args.cpu:
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
|
||||||
|
|
||||||
|
def unload_model():
|
||||||
|
shared.model = shared.tokenizer = None
|
||||||
|
clear_torch_cache()
|
||||||
|
|
||||||
|
|
||||||
|
def reload_model():
|
||||||
|
unload_model()
|
||||||
|
shared.model, shared.tokenizer = load_model(shared.model_name)
|
||||||
|
|
||||||
|
|
||||||
def load_soft_prompt(name):
|
def load_soft_prompt(name):
|
||||||
if name == 'None':
|
if name == 'None':
|
||||||
shared.soft_prompt = False
|
shared.soft_prompt = False
|
||||||
|
|||||||
@@ -1,4 +1,3 @@
|
|||||||
import gc
|
|
||||||
import re
|
import re
|
||||||
import time
|
import time
|
||||||
import traceback
|
import traceback
|
||||||
@@ -12,7 +11,7 @@ from modules.callbacks import (Iteratorize, Stream,
|
|||||||
_SentinelTokenStoppingCriteria)
|
_SentinelTokenStoppingCriteria)
|
||||||
from modules.extensions import apply_extensions
|
from modules.extensions import apply_extensions
|
||||||
from modules.html_generator import generate_4chan_html, generate_basic_html
|
from modules.html_generator import generate_4chan_html, generate_basic_html
|
||||||
from modules.models import local_rank
|
from modules.models import clear_torch_cache, local_rank
|
||||||
|
|
||||||
|
|
||||||
def get_max_prompt_length(tokens):
|
def get_max_prompt_length(tokens):
|
||||||
@@ -101,12 +100,6 @@ def formatted_outputs(reply, model_name):
|
|||||||
return reply
|
return reply
|
||||||
|
|
||||||
|
|
||||||
def clear_torch_cache():
|
|
||||||
gc.collect()
|
|
||||||
if not shared.args.cpu:
|
|
||||||
torch.cuda.empty_cache()
|
|
||||||
|
|
||||||
|
|
||||||
def set_manual_seed(seed):
|
def set_manual_seed(seed):
|
||||||
if seed != -1:
|
if seed != -1:
|
||||||
torch.manual_seed(seed)
|
torch.manual_seed(seed)
|
||||||
@@ -127,22 +120,22 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
|
|
||||||
original_question = question
|
original_question = question
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
question = apply_extensions(question, "input")
|
question = apply_extensions(question, 'input')
|
||||||
if shared.args.verbose:
|
if shared.args.verbose:
|
||||||
print(f"\n\n{question}\n--------------------\n")
|
print(f'\n\n{question}\n--------------------\n')
|
||||||
|
|
||||||
# These models are not part of Hugging Face, so we handle them
|
# These models are not part of Hugging Face, so we handle them
|
||||||
# separately and terminate the function call earlier
|
# separately and terminate the function call earlier
|
||||||
if any((shared.is_RWKV, shared.is_llamacpp)):
|
if any((shared.is_RWKV, shared.is_llamacpp)):
|
||||||
for k in ['temperature', 'top_p', 'top_k', 'repetition_penalty']:
|
for k in ['temperature', 'top_p', 'top_k', 'repetition_penalty']:
|
||||||
generate_params[k] = generate_state[k]
|
generate_params[k] = generate_state[k]
|
||||||
generate_params["token_count"] = generate_state["max_new_tokens"]
|
generate_params['token_count'] = generate_state['max_new_tokens']
|
||||||
try:
|
try:
|
||||||
if shared.args.no_stream:
|
if shared.args.no_stream:
|
||||||
reply = shared.model.generate(context=question, **generate_params)
|
reply = shared.model.generate(context=question, **generate_params)
|
||||||
output = original_question + reply
|
output = original_question + reply
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
reply = original_question + apply_extensions(reply, "output")
|
reply = original_question + apply_extensions(reply, 'output')
|
||||||
yield formatted_outputs(reply, shared.model_name)
|
yield formatted_outputs(reply, shared.model_name)
|
||||||
else:
|
else:
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
@@ -153,7 +146,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
for reply in shared.model.generate_with_streaming(context=question, **generate_params):
|
for reply in shared.model.generate_with_streaming(context=question, **generate_params):
|
||||||
output = original_question + reply
|
output = original_question + reply
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
reply = original_question + apply_extensions(reply, "output")
|
reply = original_question + apply_extensions(reply, 'output')
|
||||||
yield formatted_outputs(reply, shared.model_name)
|
yield formatted_outputs(reply, shared.model_name)
|
||||||
|
|
||||||
except Exception:
|
except Exception:
|
||||||
@@ -162,7 +155,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
t1 = time.time()
|
t1 = time.time()
|
||||||
original_tokens = len(encode(original_question)[0])
|
original_tokens = len(encode(original_question)[0])
|
||||||
new_tokens = len(encode(output)[0]) - original_tokens
|
new_tokens = len(encode(output)[0]) - original_tokens
|
||||||
print(f"Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens})")
|
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens})')
|
||||||
return
|
return
|
||||||
|
|
||||||
input_ids = encode(question, generate_state['max_new_tokens'])
|
input_ids = encode(question, generate_state['max_new_tokens'])
|
||||||
@@ -178,31 +171,30 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
t = [encode(string, 0, add_special_tokens=False) for string in stopping_strings]
|
t = [encode(string, 0, add_special_tokens=False) for string in stopping_strings]
|
||||||
stopping_criteria_list.append(_SentinelTokenStoppingCriteria(sentinel_token_ids=t, starting_idx=len(input_ids[0])))
|
stopping_criteria_list.append(_SentinelTokenStoppingCriteria(sentinel_token_ids=t, starting_idx=len(input_ids[0])))
|
||||||
|
|
||||||
generate_params["max_new_tokens"] = generate_state['max_new_tokens']
|
|
||||||
if not shared.args.flexgen:
|
if not shared.args.flexgen:
|
||||||
for k in ["do_sample", "temperature", "top_p", "typical_p", "repetition_penalty", "encoder_repetition_penalty", "top_k", "min_length", "no_repeat_ngram_size", "num_beams", "penalty_alpha", "length_penalty", "early_stopping"]:
|
for k in ['max_new_tokens', 'do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'encoder_repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping']:
|
||||||
generate_params[k] = generate_state[k]
|
generate_params[k] = generate_state[k]
|
||||||
generate_params["eos_token_id"] = eos_token_ids
|
generate_params['eos_token_id'] = eos_token_ids
|
||||||
generate_params["stopping_criteria"] = stopping_criteria_list
|
generate_params['stopping_criteria'] = stopping_criteria_list
|
||||||
if shared.args.no_stream:
|
if shared.args.no_stream:
|
||||||
generate_params["min_length"] = 0
|
generate_params['min_length'] = 0
|
||||||
else:
|
else:
|
||||||
for k in ["do_sample", "temperature"]:
|
for k in ['max_new_tokens', 'do_sample', 'temperature']:
|
||||||
generate_params[k] = generate_state[k]
|
generate_params[k] = generate_state[k]
|
||||||
generate_params["stop"] = generate_state["eos_token_ids"][-1]
|
generate_params['stop'] = generate_state['eos_token_ids'][-1]
|
||||||
if not shared.args.no_stream:
|
if not shared.args.no_stream:
|
||||||
generate_params["max_new_tokens"] = 8
|
generate_params['max_new_tokens'] = 8
|
||||||
|
|
||||||
if shared.args.no_cache:
|
if shared.args.no_cache:
|
||||||
generate_params.update({"use_cache": False})
|
generate_params.update({'use_cache': False})
|
||||||
if shared.args.deepspeed:
|
if shared.args.deepspeed:
|
||||||
generate_params.update({"synced_gpus": True})
|
generate_params.update({'synced_gpus': True})
|
||||||
if shared.soft_prompt:
|
if shared.soft_prompt:
|
||||||
inputs_embeds, filler_input_ids = generate_softprompt_input_tensors(input_ids)
|
inputs_embeds, filler_input_ids = generate_softprompt_input_tensors(input_ids)
|
||||||
generate_params.update({"inputs_embeds": inputs_embeds})
|
generate_params.update({'inputs_embeds': inputs_embeds})
|
||||||
generate_params.update({"inputs": filler_input_ids})
|
generate_params.update({'inputs': filler_input_ids})
|
||||||
else:
|
else:
|
||||||
generate_params.update({"inputs": input_ids})
|
generate_params.update({'inputs': input_ids})
|
||||||
|
|
||||||
try:
|
try:
|
||||||
# Generate the entire reply at once.
|
# Generate the entire reply at once.
|
||||||
@@ -217,7 +209,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
new_tokens = len(output) - len(input_ids[0])
|
new_tokens = len(output) - len(input_ids[0])
|
||||||
reply = decode(output[-new_tokens:])
|
reply = decode(output[-new_tokens:])
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
reply = original_question + apply_extensions(reply, "output")
|
reply = original_question + apply_extensions(reply, 'output')
|
||||||
|
|
||||||
yield formatted_outputs(reply, shared.model_name)
|
yield formatted_outputs(reply, shared.model_name)
|
||||||
|
|
||||||
@@ -244,7 +236,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
new_tokens = len(output) - len(input_ids[0])
|
new_tokens = len(output) - len(input_ids[0])
|
||||||
reply = decode(output[-new_tokens:])
|
reply = decode(output[-new_tokens:])
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
reply = original_question + apply_extensions(reply, "output")
|
reply = original_question + apply_extensions(reply, 'output')
|
||||||
|
|
||||||
if output[-1] in eos_token_ids:
|
if output[-1] in eos_token_ids:
|
||||||
break
|
break
|
||||||
@@ -262,7 +254,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
new_tokens = len(output) - len(original_input_ids[0])
|
new_tokens = len(output) - len(original_input_ids[0])
|
||||||
reply = decode(output[-new_tokens:])
|
reply = decode(output[-new_tokens:])
|
||||||
if not shared.is_chat():
|
if not shared.is_chat():
|
||||||
reply = original_question + apply_extensions(reply, "output")
|
reply = original_question + apply_extensions(reply, 'output')
|
||||||
|
|
||||||
if np.count_nonzero(np.isin(input_ids[0], eos_token_ids)) < np.count_nonzero(np.isin(output, eos_token_ids)):
|
if np.count_nonzero(np.isin(input_ids[0], eos_token_ids)) < np.count_nonzero(np.isin(output, eos_token_ids)):
|
||||||
break
|
break
|
||||||
@@ -271,10 +263,10 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
input_ids = np.reshape(output, (1, output.shape[0]))
|
input_ids = np.reshape(output, (1, output.shape[0]))
|
||||||
if shared.soft_prompt:
|
if shared.soft_prompt:
|
||||||
inputs_embeds, filler_input_ids = generate_softprompt_input_tensors(input_ids)
|
inputs_embeds, filler_input_ids = generate_softprompt_input_tensors(input_ids)
|
||||||
generate_params.update({"inputs_embeds": inputs_embeds})
|
generate_params.update({'inputs_embeds': inputs_embeds})
|
||||||
generate_params.update({"inputs": filler_input_ids})
|
generate_params.update({'inputs': filler_input_ids})
|
||||||
else:
|
else:
|
||||||
generate_params.update({"inputs": input_ids})
|
generate_params.update({'inputs': input_ids})
|
||||||
|
|
||||||
yield formatted_outputs(reply, shared.model_name)
|
yield formatted_outputs(reply, shared.model_name)
|
||||||
|
|
||||||
@@ -284,5 +276,5 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
|||||||
t1 = time.time()
|
t1 = time.time()
|
||||||
original_tokens = len(original_input_ids[0])
|
original_tokens = len(original_input_ids[0])
|
||||||
new_tokens = len(output) - original_tokens
|
new_tokens = len(output) - original_tokens
|
||||||
print(f"Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens})")
|
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens})')
|
||||||
return
|
return
|
||||||
|
|||||||
@@ -152,7 +152,7 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
|||||||
# == Prep the dataset, format, etc ==
|
# == Prep the dataset, format, etc ==
|
||||||
if raw_text_file not in ['None', '']:
|
if raw_text_file not in ['None', '']:
|
||||||
print("Loading raw text file dataset...")
|
print("Loading raw text file dataset...")
|
||||||
with open(clean_path('training/datasets', f'{raw_text_file}.txt'), 'r') as file:
|
with open(clean_path('training/datasets', f'{raw_text_file}.txt'), 'r', encoding='utf-8') as file:
|
||||||
raw_text = file.read()
|
raw_text = file.read()
|
||||||
tokens = shared.tokenizer.encode(raw_text)
|
tokens = shared.tokenizer.encode(raw_text)
|
||||||
del raw_text # Note: could be a gig for a large dataset, so delete redundant data as we go to be safe on RAM
|
del raw_text # Note: could be a gig for a large dataset, so delete redundant data as we go to be safe on RAM
|
||||||
|
|||||||
104
server.py
104
server.py
@@ -15,12 +15,11 @@ import gradio as gr
|
|||||||
from PIL import Image
|
from PIL import Image
|
||||||
|
|
||||||
import modules.extensions as extensions_module
|
import modules.extensions as extensions_module
|
||||||
from modules import chat, shared, training, ui, api
|
from modules import api, chat, shared, training, ui
|
||||||
from modules.html_generator import chat_html_wrapper
|
from modules.html_generator import chat_html_wrapper
|
||||||
from modules.LoRA import add_lora_to_model
|
from modules.LoRA import add_lora_to_model
|
||||||
from modules.models import load_model, load_soft_prompt
|
from modules.models import load_model, load_soft_prompt, unload_model
|
||||||
from modules.text_generation import (clear_torch_cache, generate_reply,
|
from modules.text_generation import generate_reply, stop_everything_event
|
||||||
stop_everything_event)
|
|
||||||
|
|
||||||
# Loading custom settings
|
# Loading custom settings
|
||||||
settings_file = None
|
settings_file = None
|
||||||
@@ -79,11 +78,6 @@ def get_available_loras():
|
|||||||
return ['None'] + sorted([item.name for item in list(Path(shared.args.lora_dir).glob('*')) if not item.name.endswith(('.txt', '-np', '.pt', '.json'))], key=str.lower)
|
return ['None'] + sorted([item.name for item in list(Path(shared.args.lora_dir).glob('*')) if not item.name.endswith(('.txt', '-np', '.pt', '.json'))], key=str.lower)
|
||||||
|
|
||||||
|
|
||||||
def unload_model():
|
|
||||||
shared.model = shared.tokenizer = None
|
|
||||||
clear_torch_cache()
|
|
||||||
|
|
||||||
|
|
||||||
def load_model_wrapper(selected_model):
|
def load_model_wrapper(selected_model):
|
||||||
if selected_model != shared.model_name:
|
if selected_model != shared.model_name:
|
||||||
shared.model_name = selected_model
|
shared.model_name = selected_model
|
||||||
@@ -330,7 +324,7 @@ def create_interface():
|
|||||||
shared.gradio['display'] = gr.HTML(value=chat_html_wrapper(shared.history['visible'], shared.settings['name1'], shared.settings['name2'], 'cai-chat'))
|
shared.gradio['display'] = gr.HTML(value=chat_html_wrapper(shared.history['visible'], shared.settings['name1'], shared.settings['name2'], 'cai-chat'))
|
||||||
shared.gradio['textbox'] = gr.Textbox(label='Input')
|
shared.gradio['textbox'] = gr.Textbox(label='Input')
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
shared.gradio['Generate'] = gr.Button('Generate')
|
shared.gradio['Generate'] = gr.Button('Generate', elem_id='Generate')
|
||||||
shared.gradio['Stop'] = gr.Button('Stop', elem_id="stop")
|
shared.gradio['Stop'] = gr.Button('Stop', elem_id="stop")
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
shared.gradio['Impersonate'] = gr.Button('Impersonate')
|
shared.gradio['Impersonate'] = gr.Button('Impersonate')
|
||||||
@@ -400,55 +394,71 @@ def create_interface():
|
|||||||
create_settings_menus(default_preset)
|
create_settings_menus(default_preset)
|
||||||
|
|
||||||
shared.input_params = [shared.gradio[k] for k in ['Chat input', 'generate_state', 'name1', 'name2', 'context', 'Chat mode', 'end_of_turn']]
|
shared.input_params = [shared.gradio[k] for k in ['Chat input', 'generate_state', 'name1', 'name2', 'context', 'Chat mode', 'end_of_turn']]
|
||||||
|
clear_arr = [shared.gradio[k] for k in ['Clear history-confirm', 'Clear history', 'Clear history-cancel']]
|
||||||
|
reload_inputs = [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']]
|
||||||
|
|
||||||
def set_chat_input(textbox):
|
def set_chat_input(textbox):
|
||||||
return textbox, ""
|
return textbox, ""
|
||||||
|
|
||||||
gen_events.append(shared.gradio['Generate'].click(set_chat_input, shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False))
|
gen_events.append(shared.gradio['Generate'].click(
|
||||||
gen_events.append(shared.gradio['Generate'].click(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
|
set_chat_input, shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False).then(
|
||||||
gen_events.append(shared.gradio['textbox'].submit(set_chat_input, shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False))
|
chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||||
gen_events.append(shared.gradio['textbox'].submit(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
|
lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False).then(
|
||||||
gen_events.append(shared.gradio['Regenerate'].click(chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
|
lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||||
|
)
|
||||||
|
|
||||||
|
gen_events.append(shared.gradio['textbox'].submit(
|
||||||
|
set_chat_input, shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False).then(
|
||||||
|
chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||||
|
lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False).then(
|
||||||
|
lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||||
|
)
|
||||||
|
|
||||||
|
gen_events.append(shared.gradio['Regenerate'].click(
|
||||||
|
chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||||
|
lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False).then(
|
||||||
|
lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||||
|
)
|
||||||
|
|
||||||
|
shared.gradio['Replace last reply'].click(
|
||||||
|
chat.replace_last_reply, [shared.gradio[k] for k in ['textbox', 'name1', 'name2', 'Chat mode']], shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||||
|
lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False).then(
|
||||||
|
lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||||
|
|
||||||
|
shared.gradio['Clear history-confirm'].click(
|
||||||
|
lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr).then(
|
||||||
|
chat.clear_chat_log, [shared.gradio[k] for k in ['name1', 'name2', 'greeting', 'Chat mode']], shared.gradio['display']).then(
|
||||||
|
lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||||
|
|
||||||
|
shared.gradio['Stop'].click(
|
||||||
|
stop_everything_event, [], [], queue=False, cancels=gen_events if shared.args.no_stream else None).then(
|
||||||
|
chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||||
|
|
||||||
|
shared.gradio['Chat mode'].change(
|
||||||
|
lambda x: gr.update(visible=x == 'instruct'), shared.gradio['Chat mode'], shared.gradio['Instruction templates']).then(
|
||||||
|
chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||||
|
|
||||||
|
shared.gradio['Instruction templates'].change(
|
||||||
|
lambda character, name1, name2, mode: chat.load_character(character, name1, name2, mode), [shared.gradio[k] for k in ['Instruction templates', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']]).then(
|
||||||
|
chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||||
|
|
||||||
|
shared.gradio['upload_chat_history'].upload(
|
||||||
|
chat.load_history, [shared.gradio[k] for k in ['upload_chat_history', 'name1', 'name2']], []).then(
|
||||||
|
chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||||
|
|
||||||
gen_events.append(shared.gradio['Impersonate'].click(chat.impersonate_wrapper, shared.input_params, shared.gradio['textbox'], show_progress=shared.args.no_stream))
|
gen_events.append(shared.gradio['Impersonate'].click(chat.impersonate_wrapper, shared.input_params, shared.gradio['textbox'], show_progress=shared.args.no_stream))
|
||||||
shared.gradio['Stop'].click(stop_everything_event, [], [], queue=False, cancels=gen_events if shared.args.no_stream else None)
|
|
||||||
|
|
||||||
shared.gradio['Copy last reply'].click(chat.send_last_reply_to_input, [], shared.gradio['textbox'], show_progress=shared.args.no_stream)
|
shared.gradio['Copy last reply'].click(chat.send_last_reply_to_input, [], shared.gradio['textbox'], show_progress=shared.args.no_stream)
|
||||||
shared.gradio['Replace last reply'].click(chat.replace_last_reply, [shared.gradio[k] for k in ['textbox', 'name1', 'name2', 'Chat mode']], shared.gradio['display'], show_progress=shared.args.no_stream)
|
|
||||||
|
|
||||||
# Clear history with confirmation
|
|
||||||
clear_arr = [shared.gradio[k] for k in ['Clear history-confirm', 'Clear history', 'Clear history-cancel']]
|
|
||||||
shared.gradio['Clear history'].click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, clear_arr)
|
shared.gradio['Clear history'].click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, clear_arr)
|
||||||
shared.gradio['Clear history-confirm'].click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr)
|
|
||||||
shared.gradio['Clear history-confirm'].click(chat.clear_chat_log, [shared.gradio[k] for k in ['name1', 'name2', 'greeting', 'Chat mode']], shared.gradio['display'])
|
|
||||||
shared.gradio['Clear history-cancel'].click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr)
|
shared.gradio['Clear history-cancel'].click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr)
|
||||||
shared.gradio['Chat mode'].change(lambda x: gr.update(visible=x == 'instruct'), shared.gradio['Chat mode'], shared.gradio['Instruction templates'])
|
|
||||||
|
|
||||||
shared.gradio['Remove last'].click(chat.remove_last_message, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], [shared.gradio['display'], shared.gradio['textbox']], show_progress=False)
|
shared.gradio['Remove last'].click(chat.remove_last_message, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], [shared.gradio['display'], shared.gradio['textbox']], show_progress=False)
|
||||||
shared.gradio['download_button'].click(chat.save_history, inputs=[], outputs=[shared.gradio['download']])
|
shared.gradio['download_button'].click(chat.save_history, inputs=[], outputs=[shared.gradio['download']])
|
||||||
shared.gradio['Upload character'].click(chat.upload_character, [shared.gradio['upload_json'], shared.gradio['upload_img_bot']], [shared.gradio['character_menu']])
|
shared.gradio['Upload character'].click(chat.upload_character, [shared.gradio['upload_json'], shared.gradio['upload_img_bot']], [shared.gradio['character_menu']])
|
||||||
|
|
||||||
# Clearing stuff and saving the history
|
|
||||||
for i in ['Generate', 'Regenerate', 'Replace last reply']:
|
|
||||||
shared.gradio[i].click(lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False)
|
|
||||||
shared.gradio[i].click(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
|
||||||
shared.gradio['Clear history-confirm'].click(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
|
||||||
shared.gradio['textbox'].submit(lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False)
|
|
||||||
shared.gradio['textbox'].submit(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
|
||||||
|
|
||||||
shared.gradio['character_menu'].change(chat.load_character, [shared.gradio[k] for k in ['character_menu', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']])
|
shared.gradio['character_menu'].change(chat.load_character, [shared.gradio[k] for k in ['character_menu', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']])
|
||||||
shared.gradio['Instruction templates'].change(lambda character, name1, name2, mode: chat.load_character(character, name1, name2, mode), [shared.gradio[k] for k in ['Instruction templates', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']])
|
|
||||||
shared.gradio['upload_chat_history'].upload(chat.load_history, [shared.gradio[k] for k in ['upload_chat_history', 'name1', 'name2']], [])
|
|
||||||
shared.gradio['upload_img_tavern'].upload(chat.upload_tavern_character, [shared.gradio['upload_img_tavern'], shared.gradio['name1'], shared.gradio['name2']], [shared.gradio['character_menu']])
|
shared.gradio['upload_img_tavern'].upload(chat.upload_tavern_character, [shared.gradio['upload_img_tavern'], shared.gradio['name1'], shared.gradio['name2']], [shared.gradio['character_menu']])
|
||||||
shared.gradio['your_picture'].change(chat.upload_your_profile_picture, [shared.gradio[k] for k in ['your_picture', 'name1', 'name2', 'Chat mode']], shared.gradio['display'])
|
shared.gradio['your_picture'].change(chat.upload_your_profile_picture, [shared.gradio[k] for k in ['your_picture', 'name1', 'name2', 'Chat mode']], shared.gradio['display'])
|
||||||
|
|
||||||
reload_inputs = [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']]
|
|
||||||
shared.gradio['upload_chat_history'].upload(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
|
||||||
shared.gradio['Stop'].click(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
|
||||||
shared.gradio['Instruction templates'].change(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
|
||||||
shared.gradio['Chat mode'].change(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
|
||||||
|
|
||||||
shared.gradio['interface'].load(None, None, None, _js=f"() => {{{ui.main_js+ui.chat_js}}}")
|
shared.gradio['interface'].load(None, None, None, _js=f"() => {{{ui.main_js+ui.chat_js}}}")
|
||||||
shared.gradio['interface'].load(lambda: chat.load_default_history(shared.settings['name1'], shared.settings['name2']), None, None)
|
shared.gradio['interface'].load(chat.load_default_history, [shared.gradio[k] for k in ['name1', 'name2']], None)
|
||||||
shared.gradio['interface'].load(chat.redraw_html, reload_inputs, [shared.gradio['display']], show_progress=True)
|
shared.gradio['interface'].load(chat.redraw_html, reload_inputs, [shared.gradio['display']], show_progress=True)
|
||||||
|
|
||||||
elif shared.args.notebook:
|
elif shared.args.notebook:
|
||||||
@@ -541,10 +551,12 @@ def create_interface():
|
|||||||
shared.gradio['interface_modes_menu'] = gr.Dropdown(choices=modes, value=current_mode, label="Mode")
|
shared.gradio['interface_modes_menu'] = gr.Dropdown(choices=modes, value=current_mode, label="Mode")
|
||||||
shared.gradio['extensions_menu'] = gr.CheckboxGroup(choices=get_available_extensions(), value=shared.args.extensions, label="Available extensions")
|
shared.gradio['extensions_menu'] = gr.CheckboxGroup(choices=get_available_extensions(), value=shared.args.extensions, label="Available extensions")
|
||||||
shared.gradio['bool_menu'] = gr.CheckboxGroup(choices=bool_list, value=bool_active, label="Boolean command-line flags")
|
shared.gradio['bool_menu'] = gr.CheckboxGroup(choices=bool_list, value=bool_active, label="Boolean command-line flags")
|
||||||
shared.gradio['reset_interface'] = gr.Button("Apply and restart the interface", type="primary")
|
shared.gradio['reset_interface'] = gr.Button("Apply and restart the interface")
|
||||||
|
|
||||||
shared.gradio['reset_interface'].click(set_interface_arguments, [shared.gradio[k] for k in ['interface_modes_menu', 'extensions_menu', 'bool_menu']], None)
|
# Reset interface event
|
||||||
shared.gradio['reset_interface'].click(lambda: None, None, None, _js='() => {document.body.innerHTML=\'<h1 style="font-family:monospace;margin-top:20%;color:lightgray;text-align:center;">Reloading...</h1>\'; setTimeout(function(){location.reload()},2500); return []}')
|
shared.gradio['reset_interface'].click(
|
||||||
|
set_interface_arguments, [shared.gradio[k] for k in ['interface_modes_menu', 'extensions_menu', 'bool_menu']], None).then(
|
||||||
|
lambda: None, None, None, _js='() => {document.body.innerHTML=\'<h1 style="font-family:monospace;margin-top:20%;color:lightgray;text-align:center;">Reloading...</h1>\'; setTimeout(function(){location.reload()},2500); return []}')
|
||||||
|
|
||||||
if shared.args.extensions is not None:
|
if shared.args.extensions is not None:
|
||||||
extensions_module.create_extensions_block()
|
extensions_module.create_extensions_block()
|
||||||
|
|||||||
Reference in New Issue
Block a user